 Institute of Applied and Computational Mathematics
IACM is one of the few research institutes in Europe dedicated to promoting the use of advanced mathematics in natural sciences and engineering
Institute of Applied and Computational Mathematics
IACM is one of the few research institutes in Europe dedicated to promoting the use of advanced mathematics in natural sciences and engineering
Data Science
ABOUT
RESEARCH AND DEVELOPMENT ACTIVITIES
-
Deep Learning and Generative AI
Deep learning: Deep learning has recently been at the forefront of artificial intelligence (AI) research and has truly revolutionized several fields of AI. Data Science Group members are actively involved in developing methods that can help us both better understand the limitations of existing deep learning approaches and also improve various aspects of their performance. They have worked on a wide variety of topics from this area, exploring both fundamental questions and practical applications. This includes, to mention a few of these topics, exploring and proposing novel deep network architectures, developing new ways of effectively transferring knowledge between networks, revisiting weight parameterizations for deep networks in order to improve their generalization capabilities, proposing novel self-supervised and few-shot learning methods, devising and applying learning approaches that advance the state-of-the-art for fundamental problems from the areas of computer vision and image analysis, making use of attention in the context of knowledge distillation, proposing hybrid (scattering-based) convolutional network architectures that allow for better representation learning and more interpretable features, as well as properly adapting deep neural networks such that they can be applied to arbitrary graph-structured data directly and can also handle structured-prediction tasks.

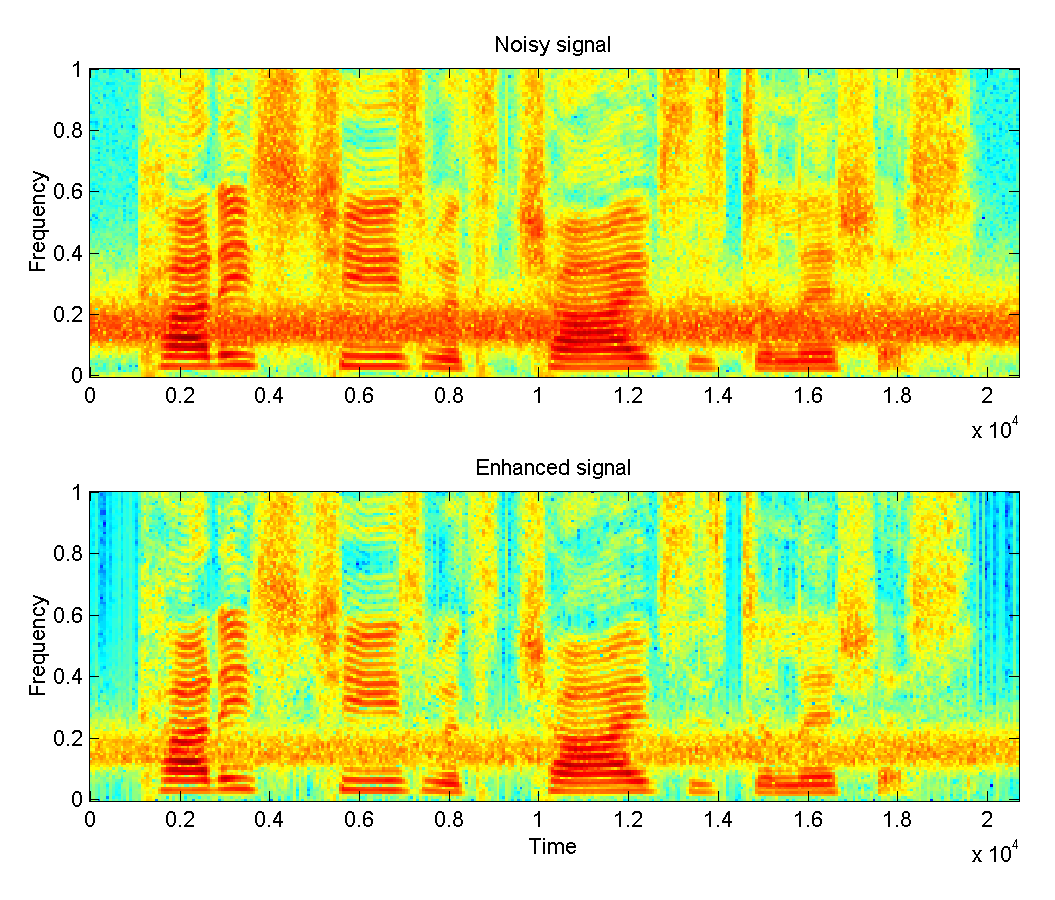
Neural-based Speech Synthesis - Deep Learning in Speech Processing: Deep Neural Networks have taken the engineering community by storm. Data-rich areas such as image processing and speech processing have been transformed during the last years. The Data Science Group combines its expertise on speech processing and applies deep learning techniques to applications such as voice conversion, speech synthesis and speech enhancement.
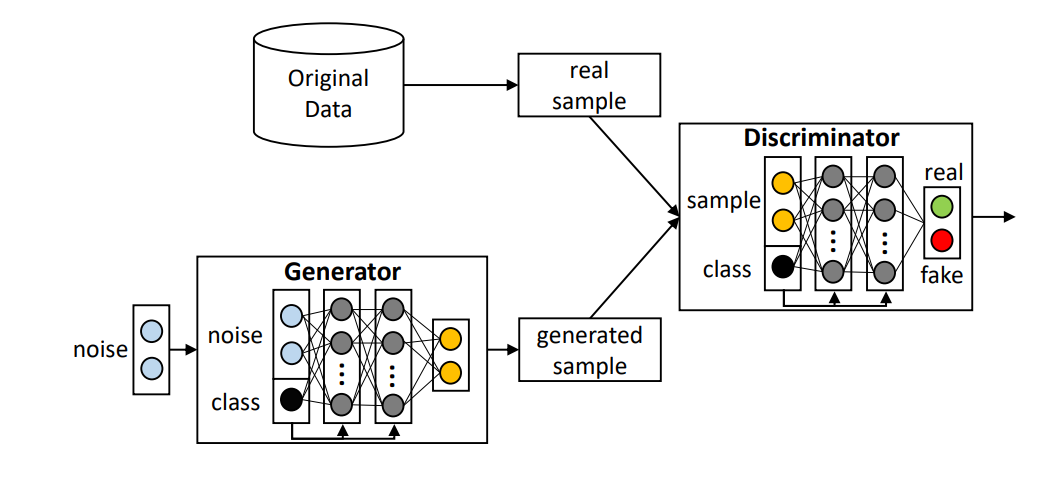
Generative Adversarial Nets - Deep Generative Learning: Generative models based on Deep Neural Nets have shown unprecedented capabilities in sampling data from complex but unknown distributions. Researchers in the Data Science Group develop novel algorithms for training generative models, focusing on Generative Adversarial Networks (GANs). GANs have been used in data augmentation schemes to generate synthetic data that follow the same distributional characteristics as the original dataset (which may contain sensitive information or limited number of cases). The proposed methodology has been applied to identify dyslexia in children, using measurements from specialized eye trackers.
- Spatial, Temporal & Spatio-temporal Statistics
- High-Dimensional and Sparse Statistics
- Uncertainty Quantification
- Additional Topics
- Journal Club on AI
- Education and Training



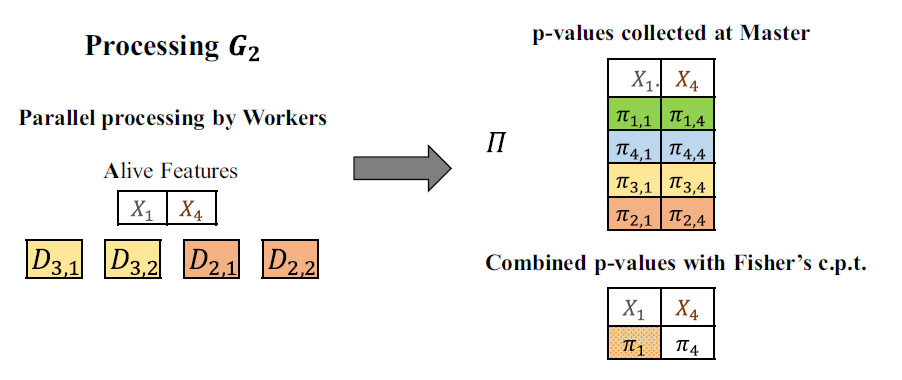
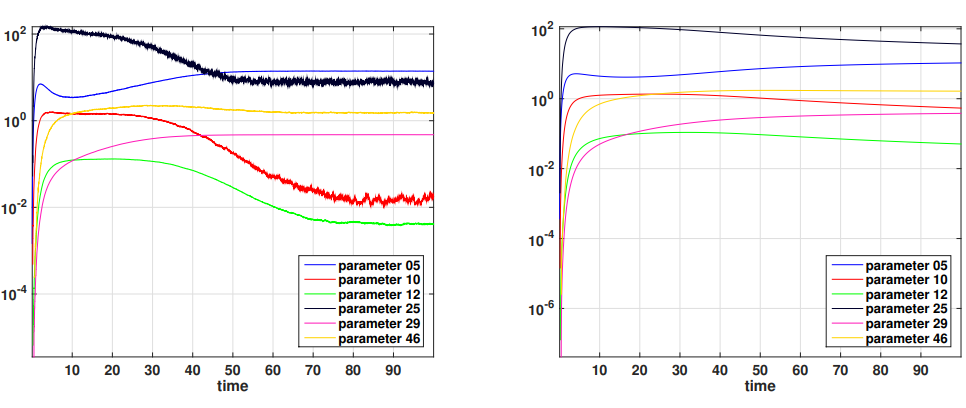
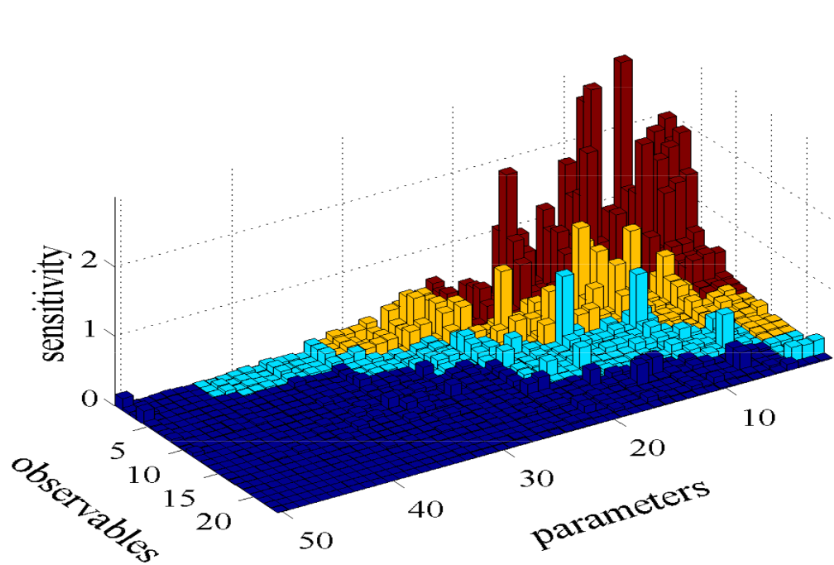
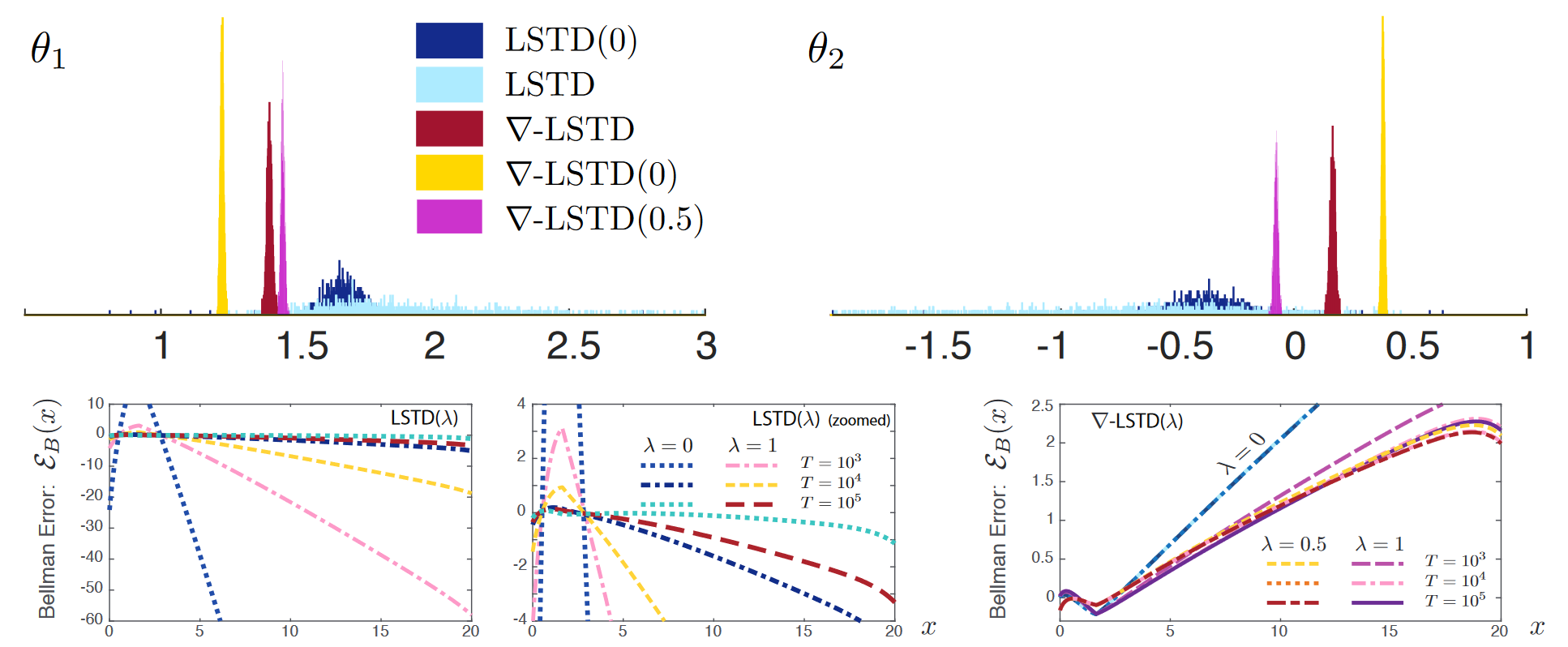
Data Science
RESEARCH AND DEVELOPMENT PROGRAMS
A. ONGOING PROJECTS
- Title: TURING: Trustworthy Unified Robust Intelligent Generative Systems
Funding Source: Horizon Europe Framework Programme (2021-2027) under the grant agreement No 101215032.
Duration: 2025-2028 - Title: ResTick: Resilience Enhancement for Ticks and Tick-Borne Diseases in Sub-Saharan Africa
Funding Source: HORIZON JU Research and Innovation Actions (in collaboration with IMBB)
Duration: 2025-2028 - Title: FOR-SOLAR: Statistical Machine learning methods for output forecasting in grid connected and off-grid PV systems
Funding Source: SAUDI ARAMCO TECHNOLOGIES COMPANY
Duration: 2025-2026 - Title: NEMO-Tools: Next-generation monitoring and mapping tools to assess marine ecosystems and biodiversity
Funding Source: Hellenic Foundation for Research and Innovation
Duration: 2024-2026 - Title: Causal discovery and inference for surrogate-assisted optimization
Funding Source and funding scheme: Research and Development Agreement among Huawei Technologies (Ireland) C.O and FORTH
Duration: 2021-2027
B. COMPLETED PROJECTS
- Title: DISENTANGLE-SPEECH: Disentangled representation learning via Mutual Information optimization with applications in speech representation learning
Funding Source: Private sector
Duration: 2024-2025 - Title: STOMA: Towards real-time, enhanced text-to-speech synthesis on the device
Funding Source: Hellenic Foundation for Research and Innovation
Duration: 2022-2025 - Title: FUSING: Biophysical tools FUSed via integrative computational approaches to decode protein foldING
Funding Source: FORTH Synergy
Duration: 2022-2024 - Title: SCALINCS: Scaling stochastic dynamics: from microscopic interactions to macroscopic phenomena
Funding Agency and funding scheme: Hellenic Foundation for Research and Innovation (H.F.R.I.) under the “First Call for H.F.R.I. Research Projects to support faculty members and researchers and the procurement of high-cost research equipment”
Duration: 2020-2024 - Title: Data Landscaping: Traffic and Mobility Data Sources of Official Statistics
Funding Source: Eurostat
Duration: 2022 - Title: SOLAR-P: Evaluation of alternative solar panel technologies, computation of irradiance daily profiles
Funding source: Saudi Aramco and KAUST
Duration: 2021-2022 - Title: Characterising population dynamics with applications in biological data
Funding source: ESPA - Department of Development
Duration: 2020-2021 - Title: WNRG: Forecasting hourly wind-farm outputs based on wind-speed predictions from alternative providers
Funding source: EREN-Hellas
Duration: 2020 - Title: ENRICH: Enriched communication across the lifespan
Funding source: EU Horizon 2020, MSCA-ETN-2020
Duration: 2017-2020
PUBLICATIONS
-
2026
- G Aletras, M Bachlitzanaki, M Stratinaki, E Foukarakis, I Petrakis, Y Pantazis, M Hamilos, K Stylianou (2026) Diuretic Resistance in Cardiorenal Syndrome: Mechanisms, Monitoring and Phenotype-Tailored Management, Frontiers in Cardiovascular Medicine, https://pubmed.ncbi.nlm.nih.gov/41561121/
- G Aletras, M Bachlitzanaki, M Stratinaki, T Georgopoulou, Y Pantazis, E Foukarakis, M Hamilos, K Stylianou (2026) Admission cardiorenal determinants of mid-term outcomes in acute heart failure, European Journal of Heart Failure 28 (Supplement_2), xuag193.855, https://doi.org/10.1093/ejhf/xuag193.855
- G Aletras, M Bachlitzanaki, M Stratinaki, E Lamprogiannakis, E Foukarakis, Y Pantazis, M Hamilos, K Stylianou (2026) Clinical phenotypes and mid-term outcomes according to precipitating factors of acute heart failure, European Journal of Heart Failure 28 (Supplement_2), xuag193.1001, https://doi.org/10.1093/ejhf/xuag193.1001
- G Aletras, M Bachlitzanaki, M Stratinaki, E Lamprogiannakis, Y Pantazis, M Hamilos, K Stylianou, E Foukarakis (2026) Early clues to long-term outcomes: predicting 180-day mortality in acute heart failure, European Journal of Preventive Cardiology 33 (Supplement_2), zwag249.057, https://doi.org/10.1093/eurjpc/zwag249.057
- G Aletras, M Bachlitzanaki, M Stratinaki, I Petrakis, Y Pantazis, E Foukarakis, M Hamilos, K Stylianou (2026) Acute Kidney Injury in Acute Heart Failure Revisited: Marker of Cardiorenal Disease Severity Rather Than Isolated Renal Injury, Life 16 (3), 486, https://doi.org/10.3390/life16030486
- G Arampatzis, A Arampatzis (2026) Multilingual Humour-Aware Retrieval with Dense and Re-Ranking Models, arXiv preprint arXiv:2605.25165
- T Aravanis, V Stojnić, B Psomas, N Komodakis, G Tolias (2026) Retrieve and Segment: Are a Few Examples Enough to Bridge the Supervision Gap in Open-Vocabulary Segmentation?, arXiv preprint arXiv:2602.23339
- S Della Corte, L Van Mieghem, A Papapantoleon, J Papazoglou-Hennig (2026) Machine learning for option pricing: an empirical investigation of network architectures, The European Journal of Finance, 1-31, https://doi.org/10.1080/1351847X.2026.2667910
- E.H. Georgoulis, A. Papapantoleon, C. Smaragdakis (2026) A deep implicit-explicit minimizing movement method for partial integro-differential equations, with application to option pricing in jump-diffusion models, Communications in Nonlinear Science and Numerical Simulation, Vol. 156, 109709, https://doi.org/10.1016/j.cnsns.2026.109709
- E Karypidis, S Gidaris, N Komodakis (2026) Representations Before Pixels: Semantics-Guided Hierarchical Video Prediction, arXiv preprint arXiv:2604.11707
- A Kofidis, Ε Dretaki, M Zotou, D Poursanidis, A Doxa, AD Mazaris, S Katsanevakis, Y Kamarianakis, Y Pantazis (2026) High-Accuracy Fish Species Identification Using Transfer Learning on Vision Foundation Models, Frontiers in Marine Science (abstract)
- N Kougioulis, N Gkorgkolis, MX Wang, B Caglayan, D Simionato, A Tonon, I Tsamardinos (2026) Large Causal Models for Temporal Causal Discovery, arXiv preprint arXiv:2602.18662
- T Kouzelis, S Gidaris, N Komodakis (2026) Coevolving Representations in Joint Image-Feature Diffusion, arXiv preprint arXiv:2604.17492
- K Lelova, GF Cooper, S Triantafillou (2026) Transportability Without Graphs: A Bayesian Approach to Identifying s-Admissible Backdoor Sets, https://openreview.net/pdf?id=XUK8q1ISCv
- OTD Nguyen, I Fotopoulos, I Tsamardinos, V Lagani, OD Røe (2026) Ever-smokers in Norway and lung cancer: median time from self-reported smoking debut to lung cancer diagnosis in eleven prospective Norwegian population studies (CONOR), ERJ Open Research, https://doi.org/10.1183/23120541.00351-2026
- M Panagopoulou, MA Papadaki, M Karaglani, T Theodosiou, K Michaelidou, S, I Tsamardinos, S Kakolyris, S, E Chatzaki (2026) Νovel methylation biomarkers in liquid biopsy and classifying biosignatures for the clinical management of breast cancer, Breast Cancer Research 28 (1), 1, https://doi.org/10.1186/s13058-025-02170-y
- B Psomas, D Christopoulos, E Baltzi, I Kakogeorgiou, T Aravanis, N Komodakis, K Karantzalos, Y Avrithis, G Tolias (2025) Attention, Please! Revisiting Attentive Probing for Masked Image Modeling, ICLR 2026, (pdf)
- C Sarafoglou, A Kofidis, M de Boer, M Mylonakis, K Mavrakis, G Zacharakis, Y Pantazis, G Gouridis (2026) NEXT-FRET maps nonequilibrium rerouting of Escherichia coli maltose-binding protein folding by its signal peptide and chaperones, Proceedings of the National Academy of Sciences 123 (20), e2529979123, https://doi.org/10.1073/pnas.2529979123
- M Tsagris, N Alharbi, A Alenazi, Y Pantazis (2026) The α–regression for compositional data: a unified framework for standard, temporal and spatial regression models including compositional predictors, https://doi.org/10.21203/rs.3.rs-9930102/v1
- 2025
- 2024
- 2023
- 2022
- 2021
- 2020
- 2019
PEOPLE
- Arampatzis Georgios, Associated Researcher
- Doxa Aggeliki, Associated Researcher
- Kalligiannaki Evangellia, Associated Researcher
- Kamarianakis Yiannis, Research Director
- Komodakis Nikos, Associated Researcher
- Loulakis Michail, Associated Researcher
- Pantazis Yannis, Principal Researcher
- Papapantoleon Antonis, Associated Researcher
- Triantafillou Sofia, Associated Researcher
- Tsamardinos Ioannis, Associated Researcher
- Biza Konstantina (PhD candidate)
- Georgoulis Elias (MSc candidate)
- Kofidis Andreas (MSc candidate)
- Litsas Anastasios (MSc candidate)
- Papadaki Maria-Eleni (MSc candidate)
- Raptakis Michail (PhD candidate)
CONTACT US
Data Science Group,
Institute of Applied and Computational Mathematics,
Foundation for Research and Technology - Hellas
Nikolaou Plastira 100, Vassilika Vouton,
GR 700 13 Heraklion, Crete
GREECE
Tel: +30 2810 391800
E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it. (Mrs. Maria Papadaki)
Tel.: +30 2810 391805
E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it. (Mrs. Yiota Rigopoulou)